
Philippine cinema has a long history with actor tandems, with love teams and action bidas/konttrabidas dominating the big screens and capturing the hearts of the Filipino masses since time immemorial. Though the flame wars and bickering between Noranians and Vilmanians have been replaced by the collective kilig-induced squirms at JaDine and KathNiel mall shows, the phenomenon is the same. Only the names have changed.

Now, not all love teams are made equal. Some simply work better than others. I’d imagine casting directors and talent management scouts have a whole science on matching starlets that optimize audience impact.
For every successful pairing like Jennylyn Mercado/ Mark Herras, there’s a not-so-successful one like Richard Gutierrez/ KC Concepcion. It’s not easy to know which love teams will work because there are a lot of factors that determine success: chemistry, appeal to the masses, and the quality of movies they star in, among others.
Predicting success is no doubt difficult, but we can focus on a simpler yet equally important problem. Across all famous love teams, action star tandems, comedy duos, which ones actually worked well? Can we objectively rank these pairings based on user acclaim?
The answer is yes. In this blog post, we will look into how we can rank actor pairings based on how their mutual presence boosts or reduces the movie’s review score. We will not look at how individual factors of the two actors (ex. their separate acting chops or popularity) play a role in success, only on the synergistic boost/reduction of their pairing.
We will use the average user reviews on IMDB to rate the movies and consequently rate the actor pairings. However, a big factor that must not be discarded is the uncertainty in the review scores. Popular and recent movies would have a ton of reviews on the site, while vintage ones would have a single-digit number of reviews. Intuitively, we need to place higher confidence on the former scores and lesser on the latter. As uncertainty plays a big role here, we need to integrate it in our modeling, leading us to the realm of Bayesian regression.
Sit back, relax, and grab your popcorn 🍿. Let’s see if your favorite love team makes the cut.
Methods
Where do we get the data?
We’ll be using IMDB to gather movie titles, actor details, and user reviews. IMDB provides a convenient data dump on their webpage, though a separate dump is made for movies, actors, and reviews. Collating a dataset for our purposes is just a matter of linking the dumps together.
As a first filter for the movies to be included in the analysis, we only consider movies released 1970 and onwards. Second, we go over all the actors in our dataset and tally how many movies each one appeared in. We only keep movies that involve at least one actor that appeared in at least 5 different movies. We do this to keep the model simple, as the presence of an actor and pairing with other actors will become covariates in the model. In total, we consider 2394 movies involving 586 different actors.
What does the data look like?
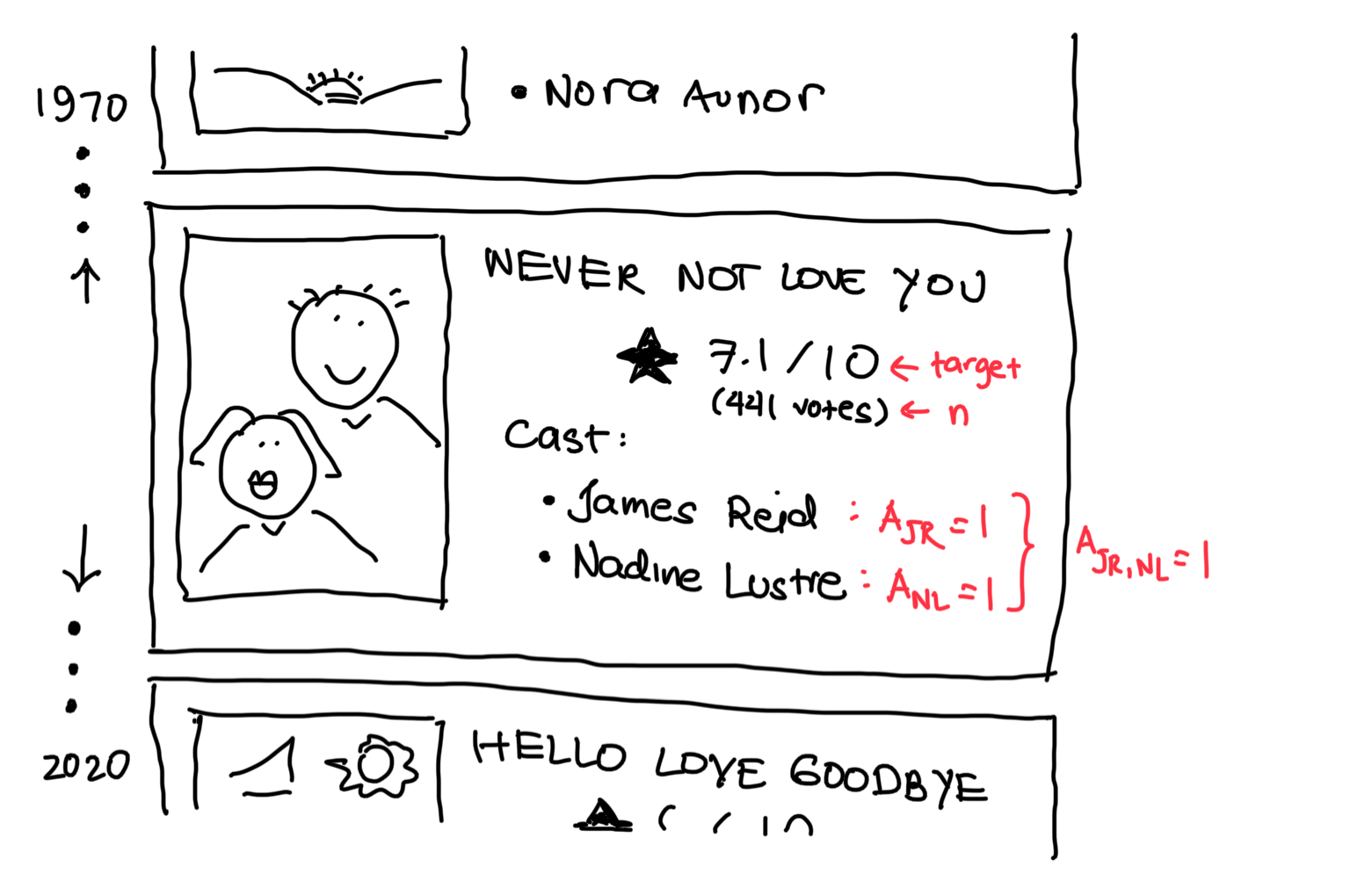
Each movie in our data set has an average rating (the target), which is the mean rating among all users that took the time to review the movie on IMDB. The dump also provides the sample size n, the number of votes that this rating averages over. This measure is a vital piece of information as it provides a measure of uncertainty over the rating. The higher the n, the more confident we are in the score.
The dump also provides the cast list for each movie, though it doesn’t seem to be exhaustive. Nevertheless, the most important actors are represented so there doesn’t seem to be any problem with it. For each of the 586 actors, we define an indicator variable A that tells whether a movie casts the actor (A=1) or not (A=0).
Since we are primarily interested in the relationship between actor pairings and user ratings, we would also need to consider the actors two at a time and define indicator variables for those. In the example, we define an indicator variable A for the pairing Nadine-James.
To be able to include actor pairings, we need to talk about interactions a bit deeper.
What are interactions?
For this analysis, what we want to measure is the relationship between the presence of an actor pair with the average user rating on IMDB, i.e. whether a specific love team leads to higher ratings than a movie that involves each actor separately.
The last sentence can be a bit confusing so let’s look at a simple example.
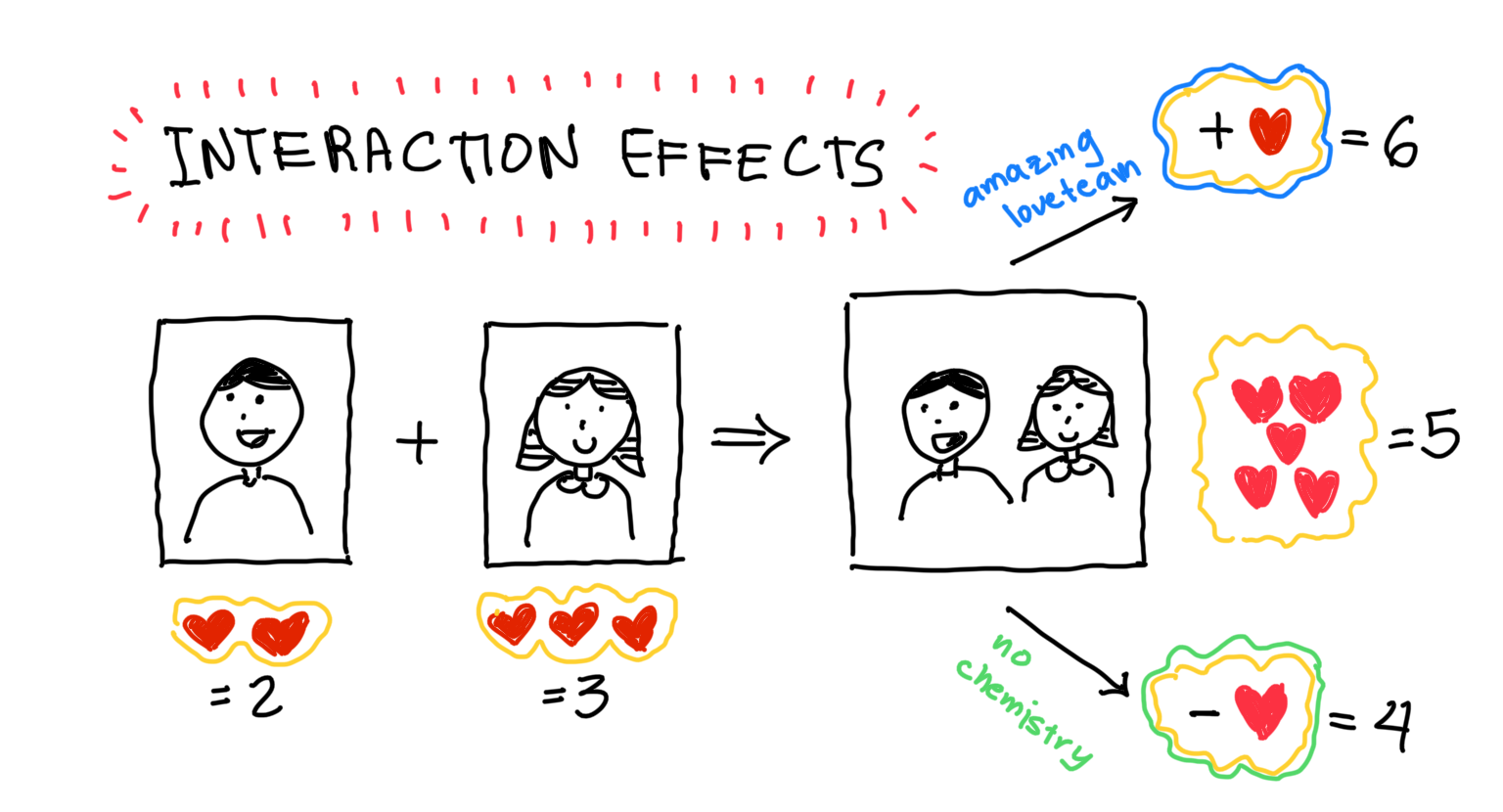
Assume that we want to find how casting different famous actors relates to the number of ❤️’s it gets, where ❤️ is a unit of critical acclaim. Let’s say that we used some data and built a simple (additive) linear regression model for this goal. Using the learned model coefficients, we find out that casting the boy adds two ❤️ to the tally and casting the girl adds three. When they’re cast together, the linearity of the model entails that the movie gets a total five ❤️.
If we cross-reference it with the training data and indeed see that the movie gets five ❤️, then we’d be happy with the model. It works well! However, there are two other probable scenarios.
Suppose that the movie is a rom-com and the two actors are up-and-coming actors cast as a love team. If the two of them have amazing chemistry and become critical favorites, the movie might get a +1 ❤️ “boost”, for a total of 6 ❤️. On the other hand, if the actors are mismatched and didn’t play off well with each other, there might be a reduction in the ❤️ count, leading to a reduced total of 4 ❤️.
In both cases, we see a synergistic effect of a love team: The total is not the sum of its parts. It’s a boost in the first case but a reduction in the second.
How do we model this? Our simple additive model that looks at individual actors does not take this phenomenon into account since it assumes that actors contribute to ratings independently. However, we can cover it by adding interaction terms in the model. We do this by defining indicator variables for actor pairs, i.e. A = 1 if the actor pair is cast in the movie and A = 0 if either or both is missing.
Using this model with interactions, we can measure the synergistic effect of love teams and actor pairings. Additionally, this effect is disentangled from the factors that concern the actors separately. In other words, we can separate the influence of the actor and the influence of the love team precisely because we assign different coefficients to them. The actor coefficient, assigned to the actor’s indicator variable, measures how his casting increases or decreases a movie’s rating, while the love team coefficient, assigned to the love team’s indicator variable, measures the rating boost or reduction when he pairs up with someone specific.
This is just a simple example to illustrate how interaction modelling can help us with our goal. The actual model that we will use is a bit more complicated.
Technical details
The model that we will be using is a hierarchical Bayesian beta regression model with interaction terms. Here it is in all its mathematical glory:
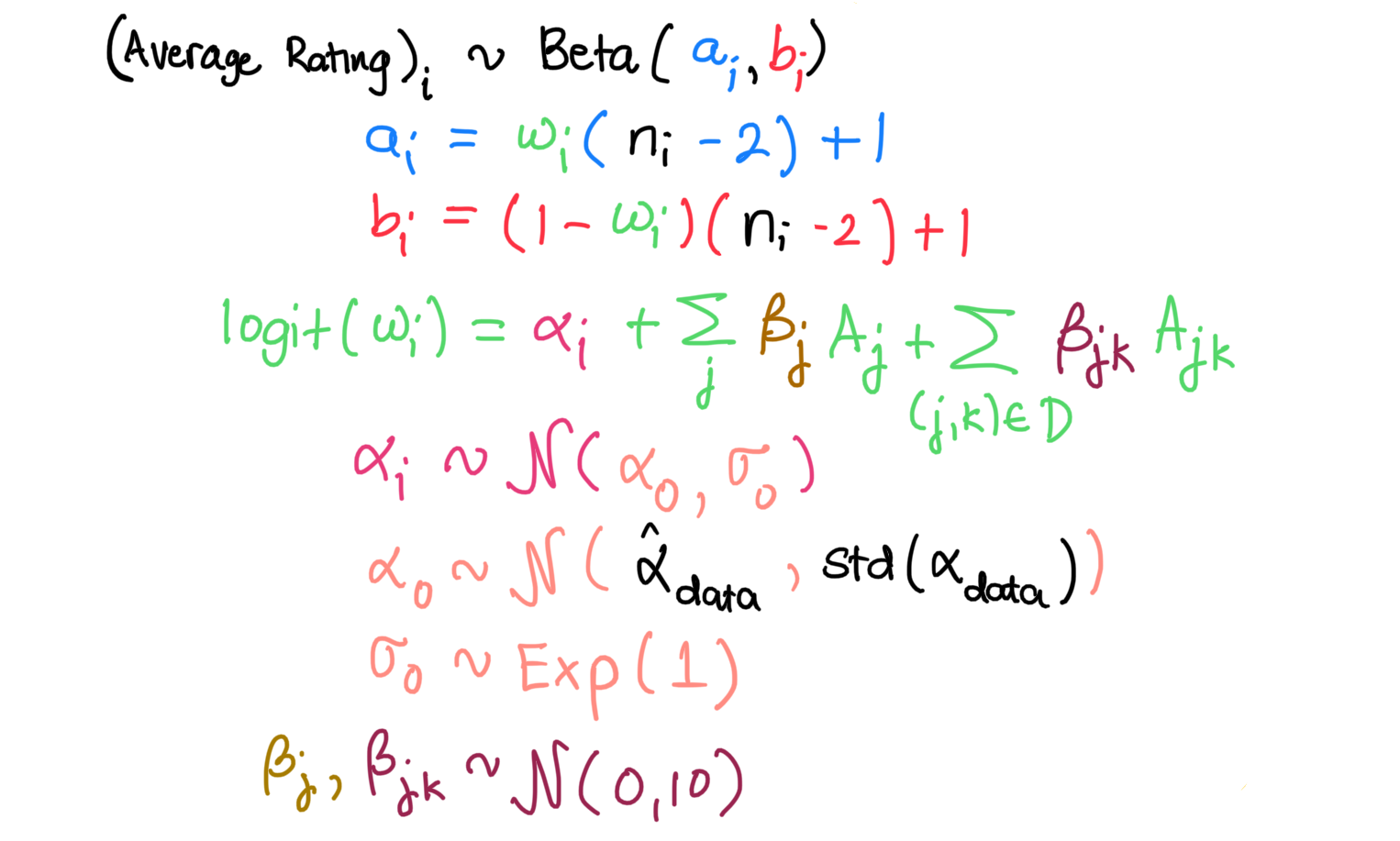
That is a bit imposing, so let’s explain it a bit.
As our observations are average ratings scaled between 0 to 1, we can use the beta distribution as our likelihood distribution. This enables us to think of the rating as a probability of critical acclaim. For the beta distribution parametrization, we will be using the mode and the concentration. I chose this as we are provided the sample size n for each movie’s average rating, so we can use n as the concentration.
The regression on actors happens on the fourth line, where we relate the mode of the beta distribution to the indicator variables for the solo actors and the actor pairs. We define beta-coefficients for each indicator variable, which are comparable in goal to the ❤’s in the previous section but have a different interpretation. I’ll elaborate more on this later. The parameters we are most interested in are the actor pairing beta-coefficients on the far right as they would tell us about the synergistic effect of the pairings.
On line four, we also see that the model also estimates a different alpha parameter for each movie. The alpha parameter is a placeholder for all unobserved factors that affect movie ratings. Since we only look at actor and actor pairings, the alpha parameter might be influenced by the movie plot, the director, cinematography, and other things that we are not interested in for analysis. The alphas for the different movies are partially pooled across all movies, all brought together by a common prior on its mean and standard deviation. The common prior parameters are estimated from the data, while the beta-coefficients are set to be weakly regularizing.
Notice the indexing set D on the fourth line. As we are dealing with 586 solo actors, considering all possible actor pairings would require us to compute 171,405 interaction pairs. Obviously this is too many and would just lead us to a sparse training data set, so I decided to only consider actor pairings that appear in at least four movies. This leads to a manageable set of 136 actor pairings.
Lastly, the model considered in the last section was an additive model, but the actual model that we will be using is a multiplicative one because of the logit link that we placed on the mode on line four. This changes the interpretation of our beta-coefficients. So instead of the presence of actors and actor pairings having an additive on the user ratings, we shift to a multiplicative effect of the exponentiated beta-coefficient on the odds-ratio of the mode of the probability of the critical acclaim. Instead of a (-,0,+) additive scale on the coefficients, we consider a (-,1,+) multiplicative scale on the exponentiated beta-coefficient. However, the basic interpretation of the higher the score, the better ratings boost still persists.
Results
Preliminaries / Bayes
As we are giving the analysis a full Bayesian treatment, I used PyMC3 to fit the model.
Why use a Bayesian model? Using one allows one to fully take into account the uncertainty inherent in the data. Instead of getting a point estimate of a love team’s effect on user ratings, a Bayesian model instead outputs a probability distribution that allows us to also model our uncertainty. This uncertainty may come from different sources. One source is our varying levels of confidence in the user ratings - many movies in IMDB have scores that average across a single-digit number of users. Another source of uncertainty may be the measured effect of love teams on the score. For example, Talk Back and Your Dead had mediocre reviews while Never Not Love You was critically acclaimed, but both movies involve the Nadine Lustre - James Reid tandem.
The goal of this analysis is to find which actor pairs and love teams work in terms of user ratings. To do that, we need to rank the pairs based on the model output. Since Bayesian models give probability distributions instead of point estimates, ranking becomes a subjective process.
One can define an appropriate loss function to find which point estimate works best for the specific purpose. However, for this study I take the easy approach of ranking the coefficient distributions based on the median, though I still show the full distribution in the visualizations to follow.
I split the results into four categories: male-male tandems, female-female tandems, male-female tandems, and love teams. For each category, I rank the medians of the exponentiated beta-coefficient distribution for each actor pair and display the top 10 and bottom 10, top to bottom. To visualize the distributions, I use a kernel-density estimate (KDE) to smoothen out the distribution (which you’ll see causes some problems).
For each plot, I superimpose a dashed line at the 1-mark, which I will refer to as the neutral mark. This signifies the transition point for a positive boost (to the right of the neutral mark) and a negative reduction (to the left) in the average IMDB score. The width of the distribution is a sign of confidence in the model estimate. The wider it is, the less confident we are of the model estimate. In addition, there are certain cases wherein the distribution variance is too high, causing problems with the KDE estimate. (See Joey de Leon - Tito Sotto and Onemig Bondoc- Red Sternberg in the Male - Male pairings plot)
Male - Male Pairings
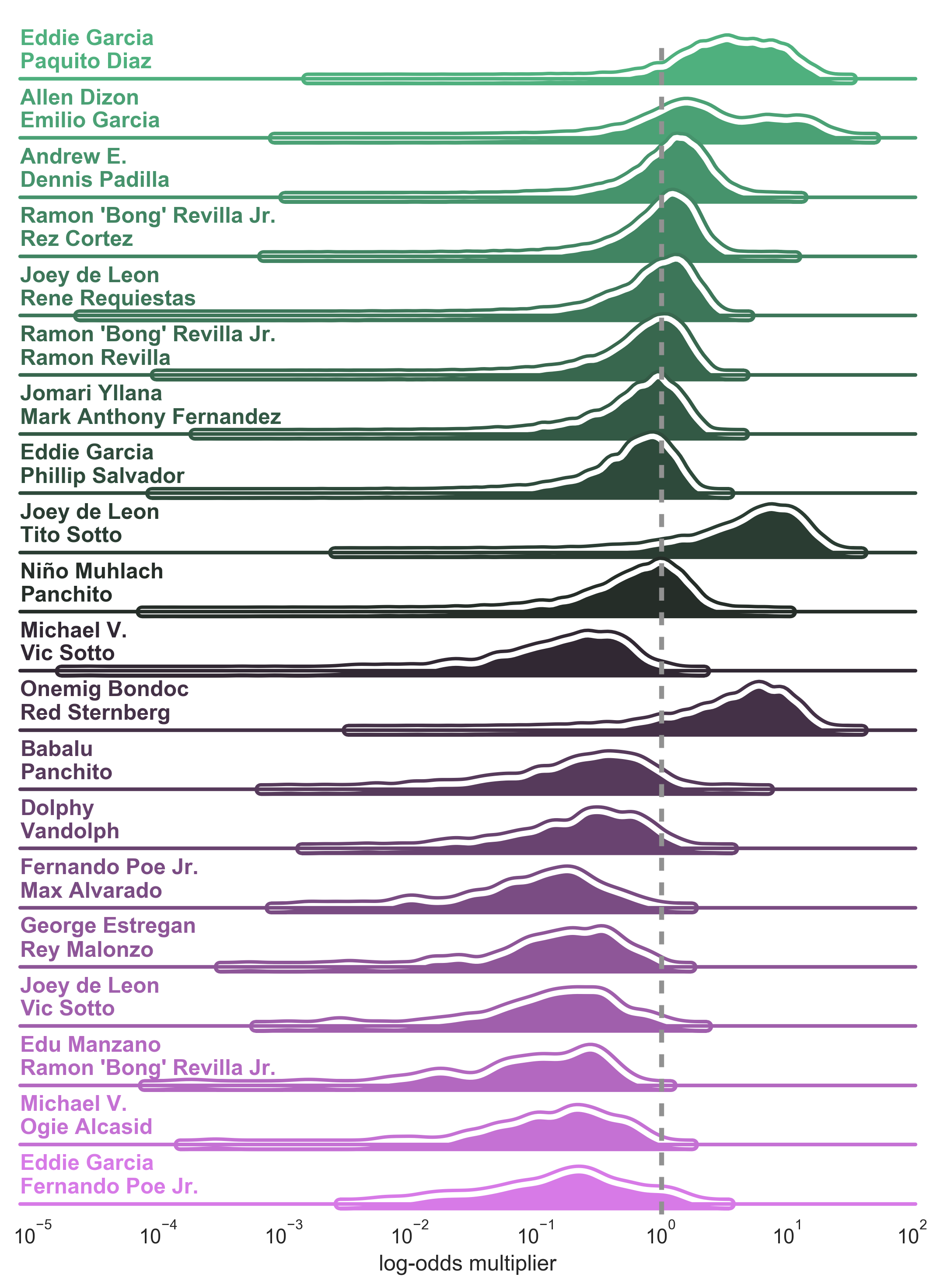
The typical male pairings in Filipino movies are usually action stars and comedy duos. Interestingly, the top and bottom pairings both involve Eddie Garcia, an 80s action star. In both pairings, Eddie Garcia usually served the role as the antagonist to the leading man, Eddie Garcia and Fernando Poe Jr. By visual inspection, it seems like only this pairing is the sure-ball positive booster as it’s the only one whose weight is lumped to the right of the neutral mark. The second and third pairings seem optimistic, but the other members of the top 10 are less certain.
The only indie pairing here is Allen Dizon and Emilio Garcia, which appears as the second best pairing. They appeared together in a string of acclaimed indie movies in the 2000s.
Do note that we are a bit more sure of the negative effect of the bottom 10 as most of their weight is situated to the left of the neutral mark. There are a lot of comedy pairings here, with Michael V and Ogie Alcasid and the father-son tandem of Dolphy and Vandolph being the most recognizable. It seems that bringing together comedy giants doesn’t really result in better or funnier movies.
Female - Female Pairings
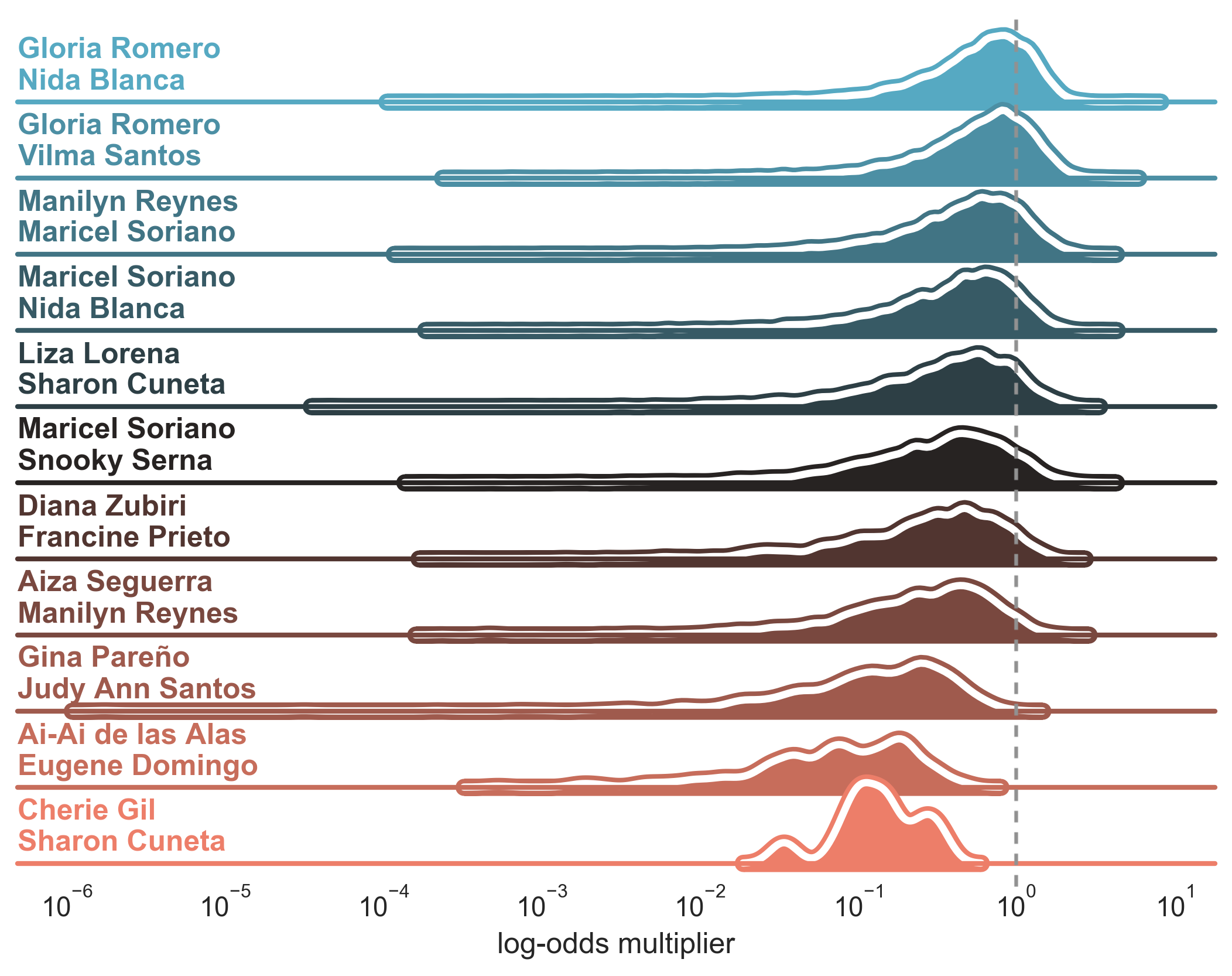
Surprisingly, there are only a few female-female pairings. After filtering out pairings that appear less than 4 times, we only retain 11 such pairs. Admittedly, it’s quite difficult to think of female-female tandem archetypes in Filipino cinema. For males, action stars and comedy duos are usual pairings. For females, it’s usually a bida-kontrabida or a protagonist-antagonist pairing in the telenovela tradition and comedy duos to a lesser extent.
Typically, Filipinos would idolize female actresses and establish fan clubs for them. Then what would happen is that the fan clubs would pit the actresses against each other, and producers would capitalize on the conflict by starring both actresses in a movie.
Basing on the distributions, it seems that female-female pairings apparently do not admit a positive boost to the average user rating (the weight of the distributions fall mostly on the left side of the neutral mark). Nevertheless, the top rated pairings both involve Gloria Romero, while the bottom rated pairing is the bida-kontrabida pairing of Sharon Cuneta and Cherie Gil.
Interestingly, there aren’t any modern (i.e 2010 onwards) female pairings. The latest ones here are the comedy tandems Ai Ai de las Alas / Eugene Domingo and comedy starlets Diana Zubiri / Francine Prieto.
Male - Female Pairings

Male-female are dominated by love teams. However, it’s very interesting to see that the top pairing belongs to Jennifer Mendoza and Ogie Alcasid, who just appeared in movies together and were not a love team. So it seems that it’s an incidental synergistic boost.
The highest rated love team here is Gary Estrada and Vina Morales, while the lowest one is Judy Ann Santos and Wowie De Guzman. Using the ranking, we can assess which love teams led to synergistic boosts in reviews and which ones led to reductions.
Similar to the female pairings, the top 10 and bottom 10 do not involve any modern pairing (the most recent one being Claudine and Rico Yan). This says something about the relative power of love teams now and then. The results suggest that the love teams of the past are associated with more dramatic boosts and reductions to the average user ratings, suggesting that the chemistry of the love team used to play a bigger role in audience reception than it does now.
Popular Love Teams
Being relatively young, I found the ranking in the previous section uninteresting as I didn’t live in the heyday of the featured love teams. To remedy that, I went through the list of love teams and hand-picked some which I was familiar with.
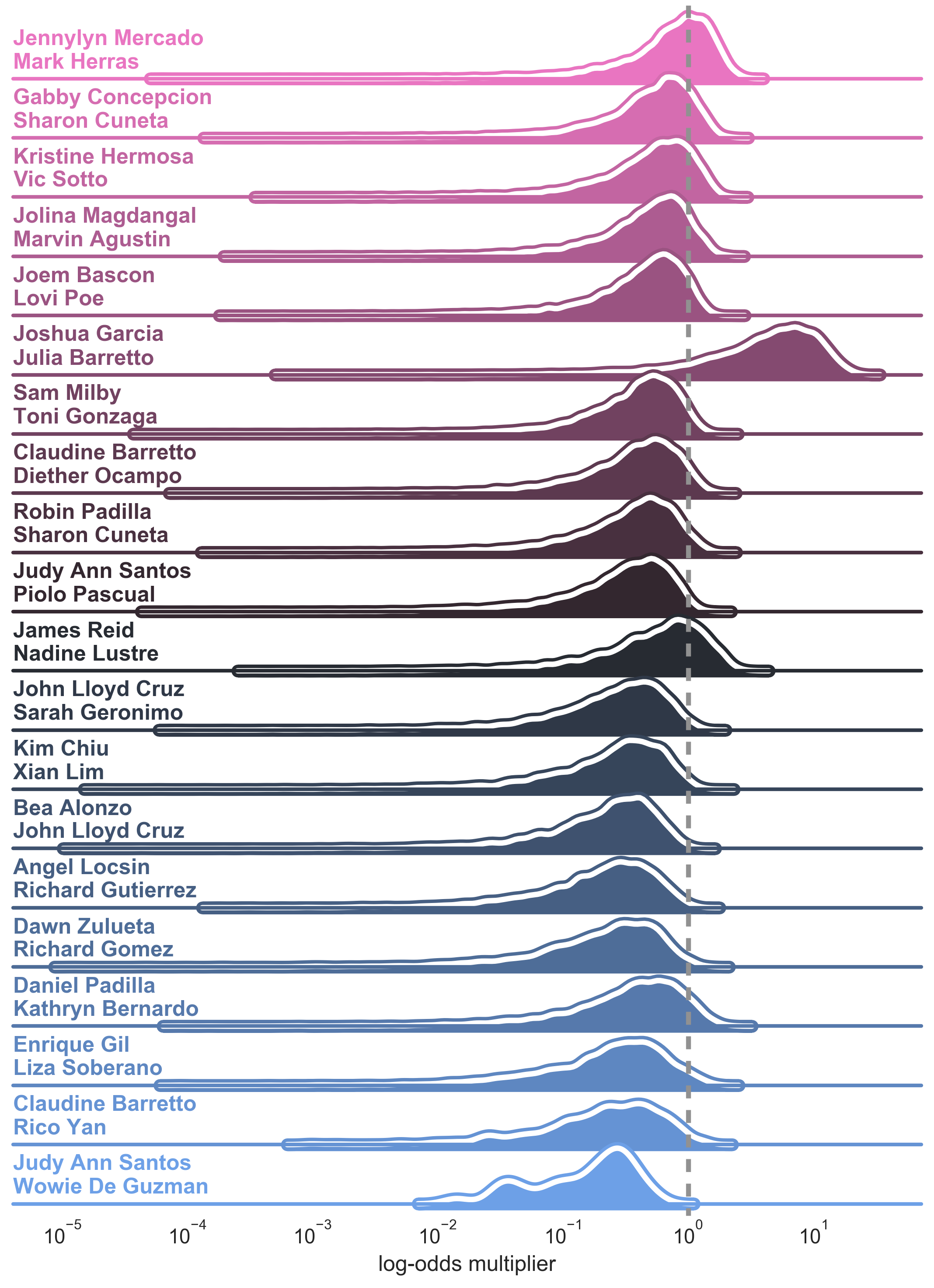
Among all love teams I was familiar with, Jennylyn Mercado / Mark Herras had the highest median boost. However, looking at the distributions, we can see that we’re not confident that the boost is positive or negative since it hovers around the neutral mark
Overall, the results suggest that there aren’t any modern love teams that boost the movie rating. Instead, there are quite a few that actually reduce the rating. From the modern love teams, Enrique Gil and Liza Soberano provide the highest median reduction, followed by Daniel Padilla and Kathryn Bernardo.
Conclusion
We calculated the synergistic boost that love teams and other actor tandems bring whenever they star in a film. Apart from the rankings that we saw in the results, I also arrived at two important observations.
First, in the history of Filipino cinema, there have only been 11 popular female-female tandems. It’s an interesting observation as typically fan clubs would pit their female idols against each other, which isn’t really conducive to having two big female stars headlining multiple movie together. On the other hand, popular male-male tandems, which are much higher in number, are dominated by action star pairings and comedy duos.
Second, comparing the model predictions between vintage and current love teams, it seems that the boost in user score associated with love teams is missing in the modern era. Simply speaking, love teams have a larger power then than now (in terms of increasing user ratings).
As I have been using IMDB ratings as the measure of movie success, it would be interesting to shift to a more tangible metric - the actual box office performance. Instead of using the movie’s quality as our success metric, it would be interesting to see how collective public reaction (i.e. number of tickets actually sold) would shift the results. Would modern love teams still lag behind their vintage equivalent? It would be interesting to see how it plays out.