

(This article is best viewed on desktop.)
It’s been several months into quarantine, and just like many of you I’ve been bored as hell. Luckily, I have video games to keep me occupied. I recently finished Dragon Quest XI on the Switch, and I must say what an amazing game. It made me feel very nostalgic of my youth, which was spent mostly in fantasy worlds. RPGs were my video game poison of choice, and Final Fantasy was the series at the top of my list.
Having played a lot of Japanese RPGs (JRPGs), it’s very easy to see that the main cast mostly follow a template: an angsty protagonist, a bubbly love interest, a comic relief, or some other variations thereof. If you think hard enough, it’s not hard to see that Cloud and Squall are basically the same archetype, ditto Wakka and Zell.

This had me thinking. Is there a way to discover these character tropes just from the things they say (i.e. their spoken lines in the game)?
By transforming this question into a data science question, we can decompose it into three subproblems:
- Can we construct a meaningful representation of JRPG characters using dialog? By meaningful, I mean that the representation admits a notion of distance so that we can measure how close or how far two characters are from each other.
- Can we identify intuitive parallel characters belonging to different games? In other words, does our representation allow us to say that Wakka (Final Fantasy X) is the Zell of Final Fantasy X?
- Can we group characters, independent of the game they are from, similar in terms of tropes?
A. Representation
In data science terms, our first subproblem is to transform game characters into vectors using a dataset of game dialog transcripts.

For this project I used character dialog from 15 major JRPGs: Final Fantasy (2, 4, 5, 6, 7, 8, 9, 10, 10-2, 12, 13-2, Tactics), Kingdom Hearts 1 and 2, and Shin Megami Tensei IV. The games were selected based on availability of game transcripts on Gamefaqs. I would have loved to include Dragon Quest XI and the Bravely games, but transcripts for these games don’t exist in an easy-to-process format.
Once I had the transcripts saved as text files, I dissected them to collect all dialog belonging to individual characters. For each game, I only considered the top 10 characters based on highest line count. In total, we have 15*10 = 150 JRPG characters, mostly the main cast for each game, but some baddies and chatty side characters as well.
Now the tricky part. The main objective is to compare different characters based on patterns of semantic and syntactic similarity in their dialog, which would become our basis to define JRPG tropes. How do we distill the essence of the character from the dialog and subsequently represent it in a vector?
We will be using the Doc2Vec algorithm.
I don’t want to get too deep on algorithms, so I won’t elaborate too much. There are tons of tutorials and articles on the web explaining the inner workings of the algorithm. Just to give a taste of it, Doc2Vec is an extension of the renowned Word2Vec algorithm. While Word2Vec transforms words into vectors (hence the name), Doc2Vec transforms documents, i.e. sets of words, into vectors.
Word2Vec looks at a huge set of texts in order to do the translation into vectors. The basic assumption of Word2Vec is the Distributional Hypothesis, which argues that the meaning of a word is based on the company it keeps. In other words, words that occur in the same context usually have similar meanings. By going over a huge set of texts and looking at each word (the target word), one at a time, and keeping track of its surrounding words (the context), one can build a simple neural network model to predict context from the target (or the target from context). Once trained, this neural network can be dissected, and one of its layers will contain an encoding for each word appearing in the training text.
A cool thing about Word2Vec is that arithmetic on word vectors is interpretable (assuming that we have good quality vectors), so one can do things like king + woman - man = queen.
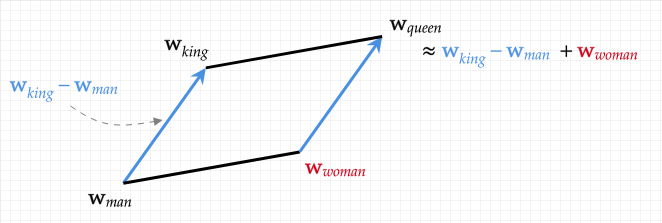
However, character dialog usually doesn’t consist of a single word (unless it’s a Pokemon). What we actually have are lines for each character: sets of words, phrases, even sentences. We can’t use Word2Vec directly on these lines, so what do we do?
Enter Doc2Vec.
The inner workings of Doc2Vec are very similar to Word2Vec, except for a small difference in the input data. Instead of training on one huge chunk of text, we use a set of labeled documents. The documents, in our case, are the different video game characters.
What’s unique about Doc2Vec is that the algorithm uses the document label as part of the context, and in terms of output we also get a vector for each document. The document vector is a representation of the syntactic and semantic tendencies of the document, and it can be used for similarity queries for other documents. For our problem, the document vector translates into a character vector which can be used to look for similar characters.
We pass in the 150 character dialog transcripts as the training data for Doc2Vec. As the output, we get a 50-dimensional vector for each character. Using this set of vectors, we can compute distances with cosine similarity, query similar characters, and explore parallels in different JRPGs.
B. Parallels
Using our character vectors, we can query for parallel characters for a particular seed character. For example, let’s see who Yuna (FF X) is closest to in each game in the dataset. (Feel free to check the results for your favorite character using the dropdown below the chart.)
It’s quite reassuring to see the results. Yuna is closest to Terra, Red XIII, Dagger, and herself (FF X-2). All these characters are soft-spoken, eloquent, and the “smart” one in the party. They have a silent confidence and are laser-focused on their goal.
The closeness rankings are satisfyingly very intuitive. Try it out on your favorite character. For example, if you select Cloud from FF VII, you’d see that Squall is at the top. They’re both angsty guys with a lot of baggage and self-conflict. Sora is close, as well as other angsty characters like Paine and Cecil.
Let’s look at Zell from FF 8, the comic relief of the party and a tough guy with a heart of gold. Barret, Zidane, Snow, Wakka and Goofy are the closest to Zell, and it’s hard to argue against this grouping.
Lastly, let’s try a villain, Merkabah from Shin Megami Tensei 4. We retrieve mostly villains from the other games, with some protagonists thrown into the mix like Auron and Donald. Thinking about it, Auron and Doanld are quite cold and cruel in their manner of speaking and can probably be mistaken as villains, just basing on the dialog.
C. Trope Clusters
Getting parallels across games was a fun exercise. What we want to do now is visualize the character vector space and locate areas belonging to specific tropes. Since our character vectors live in a 50-dimensional space, we have to bring them down to two dimensions to make sense of them easily. We will visualize the clusters with tSNE.
Let’s try it out on our character vectors.
1. Each character vector needs to be decentered from its game cluster.
(The viz is quite crowded as there are 150 characters competing for space. If you want to enlarge a particular character bubble, click on it and it’ll also bring up the name and game of origin. Click again to minimize.)
What we see makes sense but isn’t really what we want. Just acting on the raw character vectors, we see that characters of a particular game all cluster together. (Color indicates the game of origin.) Why is this the case? Characters in a particular game all talk to one another, hence the content of their dialog is probably very similar.
There are some intricacies in reading tSNE charts, but the gist is that it’s safe to interpret close pairs as more similar than far pairs.
Some interesting observations:
- Final Fantasy X/X-2 and Kingdom Hearts I/II are close in the vector space. Even though we didn’t pass information that the pair are direct sequels,
Doc2Vecwas able to pick up this relationship just from the dialog. - Final Fantasy VI and IX are close, as they share elements of high fantasy.
- Cyan from Final Fantasy VI is closer to Final Fantasy XII, while Kuja (FF IX) and ExDeath (FF V) are close to VI.
The tSNE visualization suggests that each game clusters together and has a center of mass. Therefore, if we subtract each character vector from its respective game’s center of mass, we will be able to tease out the character-dependent factor in the character vector. This character-dependent factor would be more indicative of the character’s role in the story (hero, villain) and personality (goofball, silent-type, aloof), allowing a more game-independent view of tropes.
If you click on the NEXT button in the viz, you would arrive at game-independent vectors. Notice that there are now areas belonging to certain tropes. Some examples:
- An area in the lower right contains the villain trope.
- An area in the upper right contains the female hero archetype (ex. Yuna, Aerith, Terra, Dagger)
- An area in the upper left contains the “bubbly” archetype (ex. Selphie, Rikku, Rinoa)
- An area in the upper left contains the “goofball” archetype (ex. Zell, Wakka, Barrett)
Clicking on the NEXT button one last time shades the characters based on nearest neighbors with DBSCAN, making it easier to inspect these character groups.
There are lots of interesting things in the visual, like the relatively loud Cids of KH, FF IV and VII being clustered together, far from the wise Cid of FF V (closer to Yuna), the regal Cid of IX (closer to kings) and the schoolmaster Cid of FF VIII (closer to school figures); Balthier and Irvine being close; the assistants Alyssa (FF XII-2) and Burrough (SMT 4) being close; and the lead characters in SMT IV still being close to one another after decentering, which suggests that they don’t have much of a personality to begin with (which I agree with).
D. Improvements
There are a few things that can be done to improve this project.
- A more careful preprocessing pipeline for the dialog might do wonders on the results. I took a lazy approach here and didn’t really do a lot of cleaning, so there could be some artifacts. In addition, I only considered the top 10 characters per game based on dialog line count. This means that non-chatty main characters like Kimahri (FF X) and Vincent Valentine (FF VII) were filtered out. Maybe a whitelist of characters to include would be better than just basing on the top 10?
- Adding more games would be amazing. In particular, I want to include all the mainline Final Fantasy and Dragon Quest games in the analysis.
- Improving the clustering procedure might reveal interesting tropes.