
Ah, Before Sunrise.

The *Before series is my favorite trilogy of all time. I consider it the epitome of romance on film.
Let’s kick it off with an interesting research question. Given dialog from the movie, can we determine who spoke it: Jesse or Celine? This is a basic binary classification exercise. The hard part is collecting and cleaning the data and then processing the text into machine learning features.
Since Jesse and Celine are different people (i.e. they argue and disagree a lot), it should be the case that their word usage and patterns should be quite different as well. That’s what we want to pick up with this classification task. Will we get good-enough results and be able to distinguish the speaker?
Data Source
For this exercise, we will be using all spoken lines from Before Sunrise and Before Sunset. Let’s leave out Before Midnight for the moment. I’m having a hard time scraping and cleaning the last one’s dialog. For the first two movies, scripts are directly available from the Before wiki.
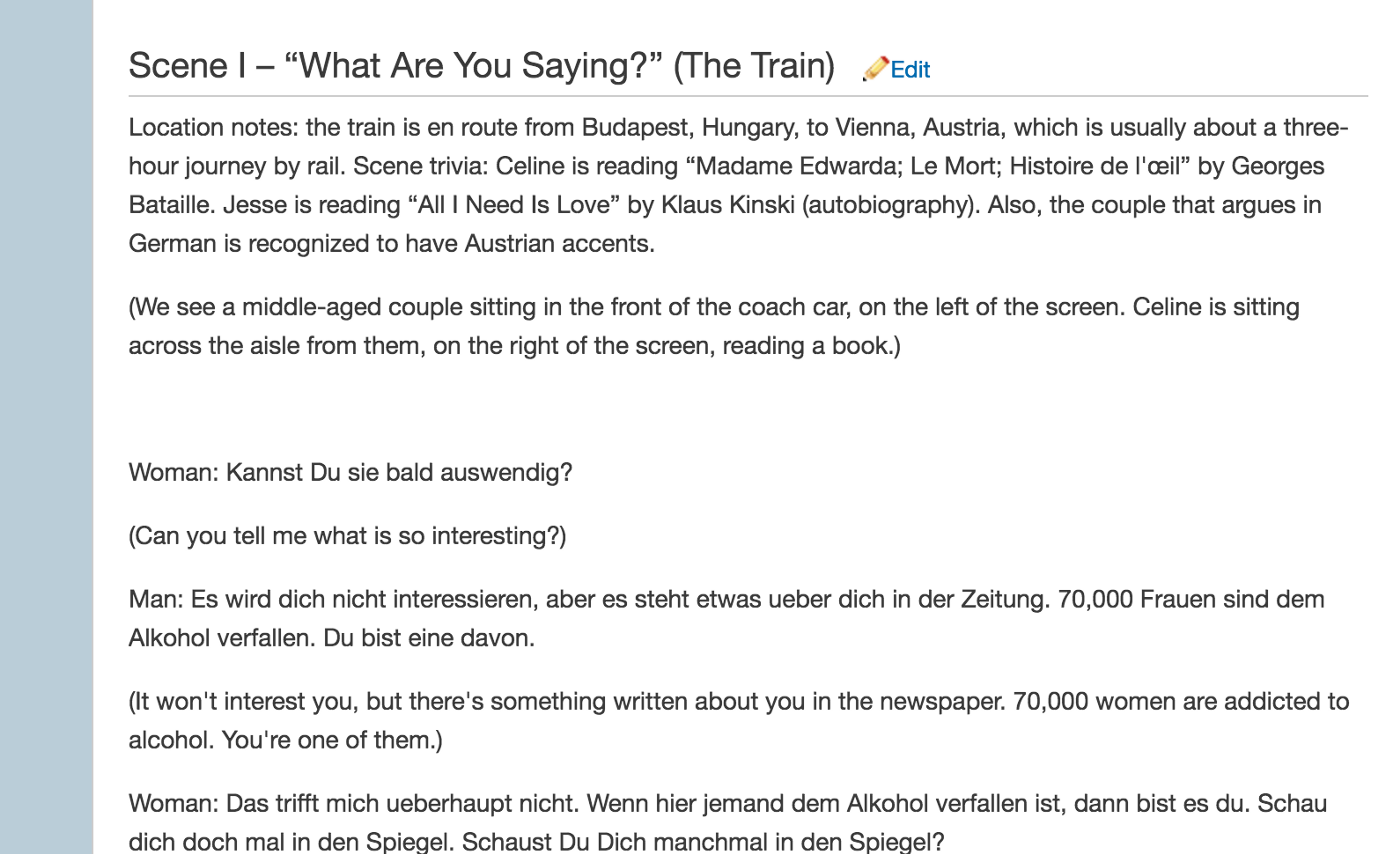
I used Beautiful Soup to parse the HTML and return speaker-dialog tuples. The third movie’s script is available as a PDF somewhere in the net, but it’s really hard to process it in a suitable way.
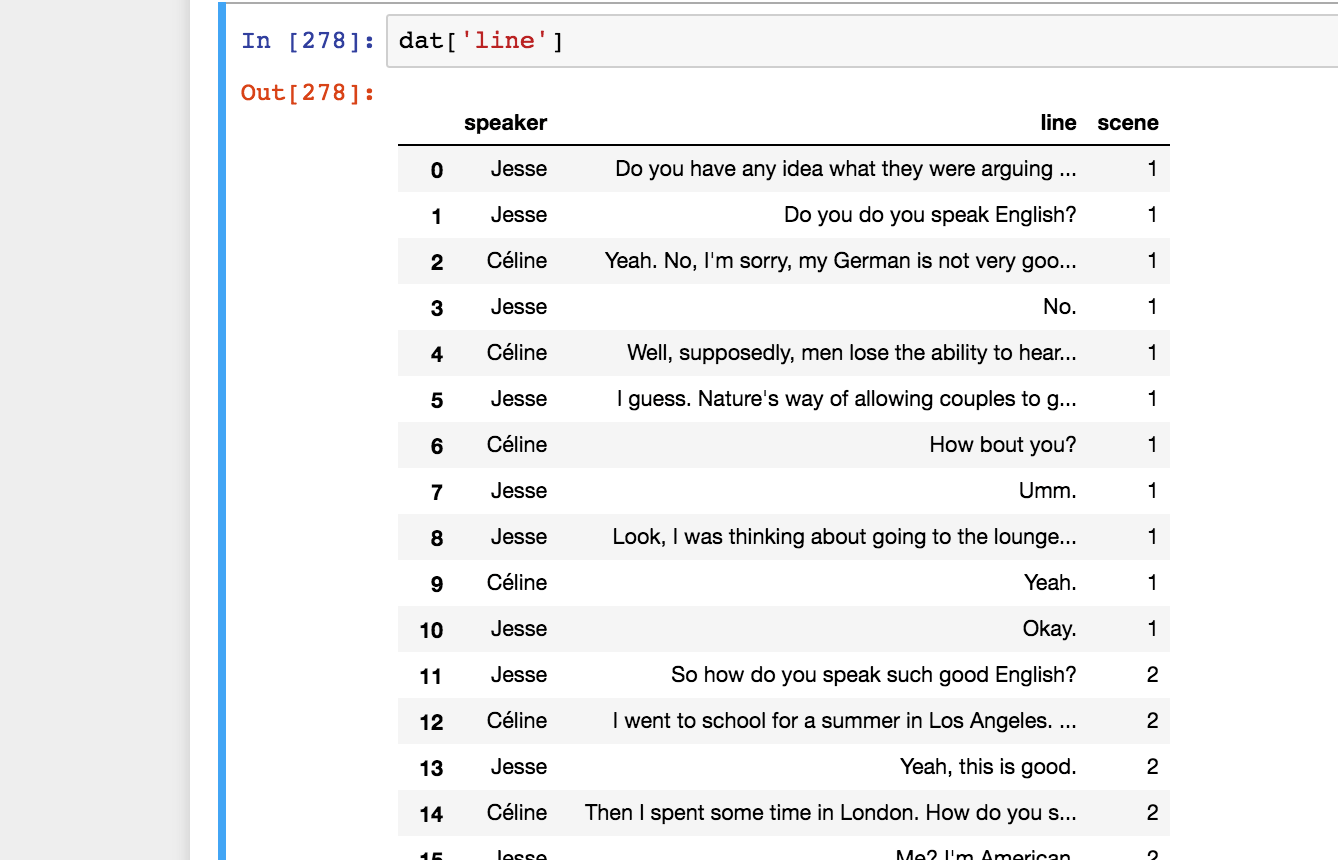
I stored all dialog tuples into a single Pandas dataframe and filtered out lines that had less than three words. I had to do this because ‘Hi’ and ‘Okay thanks’ aren’t really that distinctive and would just add to the noise in our classification task. In total, I ended up with 1,024 lines with an even split for Jesse and Celine. Coincidence? I know not.
Modeling
We’ll be using a simple feedforward neural network built on Keras as our classification model. I initially thought of passing the words through a Word2Vec embedding layer, but I realized that it doesn’t really make much sense to do that. Word2Vec encodes the semantics of text, but what we actually want to detect is more syntactic, something much shallower. Based on this hypothesis, a simple unigram bag-of-words representation is sufficient representation for this task.
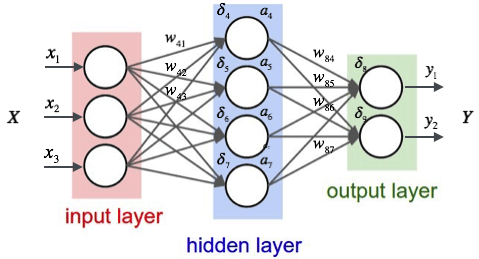
I don’t want to bog you down with details on model selection, but I tried out two- and three-layer nets under 10-fold cross-validation. The best-performing one was a three-layer net with 32 hidden units each. I also placed a 0.5-dropout layer between the first two layers to have some regularization.
Results
Currently, the best-performing model is sitting at 86% training accuracy and 62% test accuracy average over 10 folds. The model is obviously not all that amazing, but at least it’s doing better than random guessing by 12%.
We can use the model to tell us whether some not-before-seen line is more likely to be uttered by Jesse or Celine. Let’s try out lines from the third movie, which is not part of our training set.
Just keep practicing the piano, okay?, You’re really good and they spend so, much time at that school of yours… just remember that music is actually, something you will use in your life., Right, and don’t forget to — you, want those sesame things, right?, They re really good. -Jesse
The model predicts a 67% chance that Jesse said that. Cool.
Two kitties., Every time, every year two cats.,I mean it was just…, amazing. Then one day, I was around,, 30 and I was having lunch with my,, Dad, I was remembering, mentioning little Cleopatra and he was like -,, the hardest thing I ever had to do,, was to kill those cute little kittens’-,, and I was like WHAT?,,It turns out– listen to this–there were sometimes,, up to 7 kittens in that litter. - Celine
The model predicts Celine with 70% probability.
You’re so corny! Sometimes I’m just like… -Celine
… but the model predicts Jesse with 52% probability.
Let’s make no illusions. The classifier is still quite shitty at the moment and there are lots of things we can do to improve.

To Do
Well, I’m not confident that we will be able to obtain extremely high accuracy given that we only have a maximum of three movies worth of script to train on. We have to let Richard Linklater know that we need more data so he has to release Before 4. 🙂
What can we do to improve our results?
- Include Before Midnight into our training data. Obviously, this will improve our results. At this point, the more lines we have, the better.
- Include bigrams in our bag-of-words model. Jesse and Celine might be using distinct word pairs, and this could distinguish between the two. Who knows?
- Sentiment might be something interesting to use as a feature. Jesse is a lot more mellow than Celine, and this could potentially be encoded in the sentiment of their words.
- Try out more complex ML algorithms. Random forests are nonparametric models that historically have done really well on binary classification tasks.
As always, my code is up on Github.