Uncovering Effective Love Teams Using Bayesian Beta Regression with Interactions
January 3, 2021
 A deep dive into Bayesian interaction modeling to uncover which Pinoy love teams and actor tandems bring a synergistic boost to the movies they star in.
A deep dive into Bayesian interaction modeling to uncover which Pinoy love teams and actor tandems bring a synergistic boost to the movies they star in.

+ a travelogue
January 3, 2021
A deep dive into Bayesian interaction modeling to uncover which Pinoy love teams and actor tandems bring a synergistic boost to the movies they star in.
October 26, 2020
 Testing GPT-2 and Plug and Play Language Models by generating Harry Potter text steered towards certain topics.
Testing GPT-2 and Plug and Play Language Models by generating Harry Potter text steered towards certain topics.
September 1, 2020
 We uncover common character archetypes from Final Fantasy and other JRPGs using video game transcripts and Doc2Vec.
We uncover common character archetypes from Final Fantasy and other JRPGs using video game transcripts and Doc2Vec.
April 15, 2020
 We scan through Survivor voting patterns from Borneo to Island of the Idols and estimate hit rates using Bayesian hierarchical models.
We scan through Survivor voting patterns from Borneo to Island of the Idols and estimate hit rates using Bayesian hierarchical models.
July 9, 2018
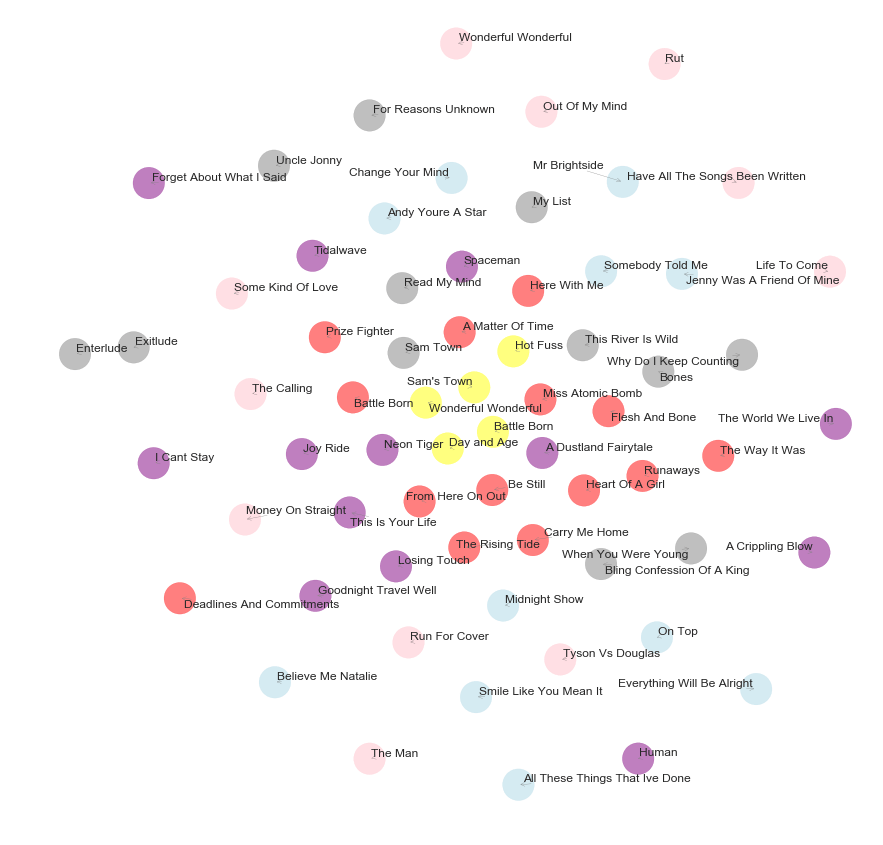 We utilize basic natural language processing to probe the lyrics of The Killers and Lana Del Rey.
We utilize basic natural language processing to probe the lyrics of The Killers and Lana Del Rey.
June 10, 2018
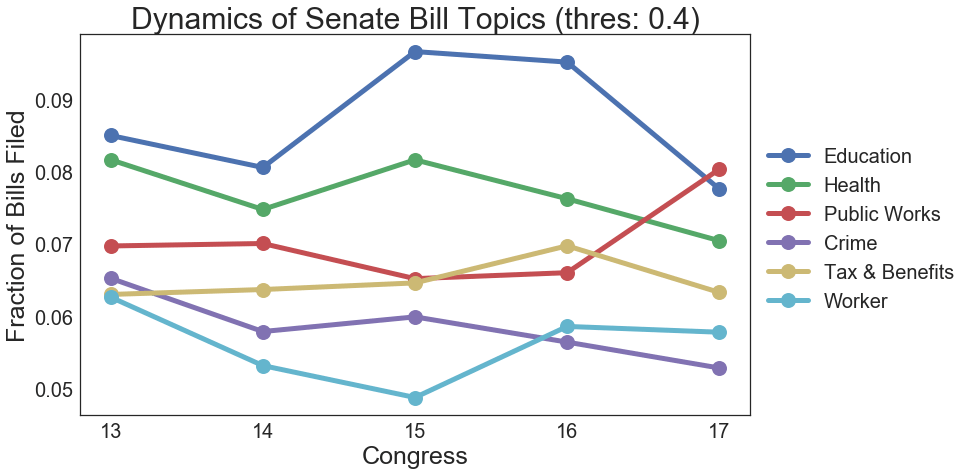 A segue into computational social science. I scrape 14,741 Philippines Senate bills written by the 13th Congress to the 17th Congress and build a topic model to understand how the topics of Senate bills have changed over time.
A segue into computational social science. I scrape 14,741 Philippines Senate bills written by the 13th Congress to the 17th Congress and build a topic model to understand how the topics of Senate bills have changed over time.